การพัฒนา YOLO (You Only Look Once) มีการปรับปรุงและพัฒนาอย่างต่อเนื่องในแต่ละเวอร์ชัน ซึ่งแต่ละเวอร์ชันมีความแตกต่างกันในด้านโครงสร้างโมเดล ความแม่นยำ ความเร็ว และฟีเจอร์อื่น ๆ ดังนี้
 YOLOv1
YOLOv1
เปิดตัว: ปี 2016
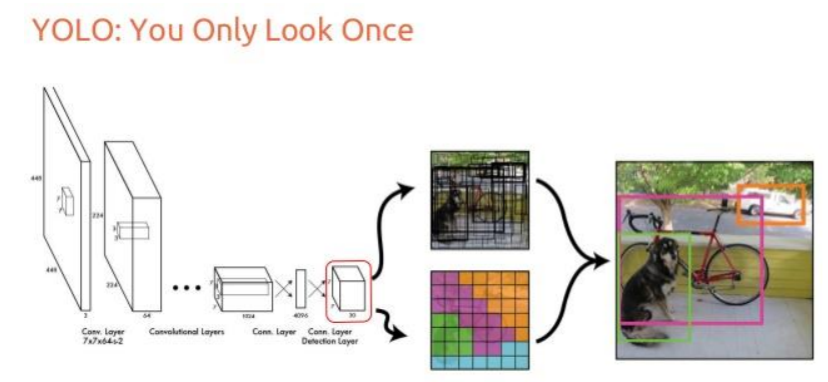
โครงสร้าง: ใช้ CNN (Convolutional Neural Network) แบบง่าย ๆ โดยแบ่งภาพออกเป็นกริด และทำการคาดการณ์ตำแหน่งของวัตถุในแต่ละกริด
ข้อดี: เป็นโมเดลแรกที่สามารถประมวลผลวัตถุในภาพได้ในเวลาเดียวกัน ทำให้มีความเร็วสูง
ข้อเสีย: ความแม่นยำต่ำในกรณีที่วัตถุอยู่ใกล้กัน เนื่องจากการแบ่งกริดทำให้ไม่สามารถตรวจจับวัตถุที่มีขนาดเล็กได้ดี
YOLOv2 (หรือ YOLO9000)
เปิดตัว: ปี 2016
โครงสร้าง: ปรับปรุงจาก YOLOv1 โดยเพิ่มความลึกของโมเดลและใช้เทคนิคใหม่ ๆ เช่น Batch Normalization และ Anchor Boxes
ข้อดี: เพิ่มความแม่นยำในการจำแนกวัตถุและสามารถตรวจจับได้มากถึง 9000 คลาส
ข้อเสีย: ยังคงมีข้อจำกัดในการจำแนกวัตถุที่มีขนาดเล็กหรือถูกรบกวนจากวัตถุอื่น
YOLOv3
เปิดตัว: ปี 2018
โครงสร้าง: ใช้ Darknet-53 ซึ่งมีความลึกมากกว่า YOLOv2 โดยใช้ Residual Blocks เพื่อช่วยในการเรียนรู้
ข้อดี: ความแม่นยำสูงขึ้น มีการตรวจจับวัตถุในหลายขนาด เนื่องจากมีการใช้การประมวลผลที่แตกต่างกันในหลายระดับ
ข้อเสีย: อาจจะมีการใช้ทรัพยากรมากขึ้นจากการเพิ่มความลึกของโมเดล
YOLOv4
เปิดตัว: ปี 2020
โครงสร้าง: ใช้เทคนิคใหม่ ๆ เช่น Mish activation function, Self-adversarial training, และการปรับปรุงการใช้ข้อมูล
ข้อดี: เพิ่มความเร็วและความแม่นยำในการตรวจจับวัตถุ โดยสามารถทำงานได้ดีแม้ในสภาพแวดล้อมที่ไม่ค่อยมีแสง
ข้อเสีย: ความซับซ้อนของโมเดลอาจทำให้การตั้งค่าและการฝึกซับซ้อนขึ้น
YOLOv5
เปิดตัว: ปี 2020 (โดย Ultralytics)
โครงสร้าง: มีการปรับปรุงโมเดลให้เหมาะสมกับการใช้งานในหลากหลายแพลตฟอร์ม โดยมีขนาดโมเดลที่สามารถเลือกได้ตามความต้องการ (เช่น YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x)
ข้อดี: ง่ายต่อการใช้งาน มีการปรับปรุงประสิทธิภาพในการตรวจจับวัตถุ และมีฟีเจอร์ใหม่ ๆ เช่น AutoAnchor, และการประมวลผลภาพหลายรูปแบบ
ข้อเสีย: อาจจะมีความสับสนในการเลือกเวอร์ชันที่เหมาะสมกับความต้องการ
YOLOv6
เปิดตัว: ปี 2022
โครงสร้าง: พัฒนาเพิ่มเติมจาก YOLOv5 โดยเน้นไปที่การเพิ่มความเร็วและความแม่นยำ
ข้อดี: มีการปรับปรุงให้สามารถทำงานได้ดีในสภาพแวดล้อมที่ท้าทาย มีการเพิ่มฟีเจอร์ใหม่ ๆ เช่น Focal Loss เพื่อเพิ่มความแม่นยำในวัตถุที่เล็ก
ข้อเสีย: ยังอยู่ในช่วงพัฒนาและอาจจะมีบั๊กหรือปัญหาในการใช้งาน

ความแม่นยำ: เพิ่มขึ้นในแต่ละเวอร์ชัน โดยเฉพาะ YOLOv4 และ YOLOv5
ความเร็ว: YOLO มีชื่อเสียงในด้านความเร็ว และในเวอร์ชันใหม่ ๆ ก็มีการปรับปรุงให้เร็วยิ่งขึ้น
ความซับซ้อน: ในขณะที่เวอร์ชันใหม่ ๆ มีความซับซ้อนมากขึ้น แต่ก็มีการให้เครื่องมือและเอกสารที่ช่วยให้ใช้ได้ง่ายขึ้น
การเลือกใช้ YOLO เวอร์ชันใดขึ้นอยู่กับความต้องการและข้อกำหนดของโปรเจกต์นั้น ๆ ตัวอย่างเช่น หากต้องการการตรวจจับที่รวดเร็วในสภาพแวดล้อมที่ไม่ซับซ้อน YOLOv3 หรือ YOLOv4 อาจจะเพียงพอ แต่ถ้าต้องการความแม่นยำสูงในสภาพแวดล้อมที่ซับซ้อน YOLOv5 หรือ YOLOv6 จะเป็นทางเลือกที่ดีกว่า
YOLO คืออะไร ความแตกต่าง ของ แต่ละ version
YOLO หรือ "You Only Look Once" เป็นอัลกอริทึมการตรวจจับวัตถุแบบเรียลไทม์ที่มีประสิทธิภาพสูงในด้านความเร็วและความแม่นยำ ถูกพัฒนาขึ้นครั้งแรกในปี 2015 โดย Joseph Redmon และทีมวิจัย YOLO ได้รับความนิยมอย่างมากในวงการคอมพิวเตอร์วิชั่นและการเรียนรู้ของเครื่อง เนื่องจากสามารถตรวจจับวัตถุได้หลายชนิดพร้อมกันในภาพเดียวอย่างรวดเร็ว

YOLO คืออะไร ความแตกต่าง ของ แต่ละ version
YOLOv1
เปิดตัว: ปี 2016
โครงสร้าง: ใช้ CNN (Convolutional Neural Network) แบบง่าย ๆ โดยแบ่งภาพออกเป็นกริด และทำการคาดการณ์ตำแหน่งของวัตถุในแต่ละกริด
ข้อดี: เป็นโมเดลแรกที่สามารถประมวลผลวัตถุในภาพได้ในเวลาเดียวกัน ทำให้มีความเร็วสูง
ข้อเสีย: ความแม่นยำต่ำในกรณีที่วัตถุอยู่ใกล้กัน เนื่องจากการแบ่งกริดทำให้ไม่สามารถตรวจจับวัตถุที่มีขนาดเล็กได้ดี
YOLOv2 (หรือ YOLO9000)
เปิดตัว: ปี 2016
โครงสร้าง: ปรับปรุงจาก YOLOv1 โดยเพิ่มความลึกของโมเดลและใช้เทคนิคใหม่ ๆ เช่น Batch Normalization และ Anchor Boxes
ข้อดี: เพิ่มความแม่นยำในการจำแนกวัตถุและสามารถตรวจจับได้มากถึง 9000 คลาส
ข้อเสีย: ยังคงมีข้อจำกัดในการจำแนกวัตถุที่มีขนาดเล็กหรือถูกรบกวนจากวัตถุอื่น
YOLOv3
เปิดตัว: ปี 2018
โครงสร้าง: ใช้ Darknet-53 ซึ่งมีความลึกมากกว่า YOLOv2 โดยใช้ Residual Blocks เพื่อช่วยในการเรียนรู้
ข้อดี: ความแม่นยำสูงขึ้น มีการตรวจจับวัตถุในหลายขนาด เนื่องจากมีการใช้การประมวลผลที่แตกต่างกันในหลายระดับ
ข้อเสีย: อาจจะมีการใช้ทรัพยากรมากขึ้นจากการเพิ่มความลึกของโมเดล
YOLOv4
เปิดตัว: ปี 2020
โครงสร้าง: ใช้เทคนิคใหม่ ๆ เช่น Mish activation function, Self-adversarial training, และการปรับปรุงการใช้ข้อมูล
ข้อดี: เพิ่มความเร็วและความแม่นยำในการตรวจจับวัตถุ โดยสามารถทำงานได้ดีแม้ในสภาพแวดล้อมที่ไม่ค่อยมีแสง
ข้อเสีย: ความซับซ้อนของโมเดลอาจทำให้การตั้งค่าและการฝึกซับซ้อนขึ้น
YOLOv5
เปิดตัว: ปี 2020 (โดย Ultralytics)
โครงสร้าง: มีการปรับปรุงโมเดลให้เหมาะสมกับการใช้งานในหลากหลายแพลตฟอร์ม โดยมีขนาดโมเดลที่สามารถเลือกได้ตามความต้องการ (เช่น YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x)
ข้อดี: ง่ายต่อการใช้งาน มีการปรับปรุงประสิทธิภาพในการตรวจจับวัตถุ และมีฟีเจอร์ใหม่ ๆ เช่น AutoAnchor, และการประมวลผลภาพหลายรูปแบบ
ข้อเสีย: อาจจะมีความสับสนในการเลือกเวอร์ชันที่เหมาะสมกับความต้องการ
YOLOv6
เปิดตัว: ปี 2022
โครงสร้าง: พัฒนาเพิ่มเติมจาก YOLOv5 โดยเน้นไปที่การเพิ่มความเร็วและความแม่นยำ
ข้อดี: มีการปรับปรุงให้สามารถทำงานได้ดีในสภาพแวดล้อมที่ท้าทาย มีการเพิ่มฟีเจอร์ใหม่ ๆ เช่น Focal Loss เพื่อเพิ่มความแม่นยำในวัตถุที่เล็ก
ข้อเสีย: ยังอยู่ในช่วงพัฒนาและอาจจะมีบั๊กหรือปัญหาในการใช้งาน
ความแม่นยำ: เพิ่มขึ้นในแต่ละเวอร์ชัน โดยเฉพาะ YOLOv4 และ YOLOv5
ความเร็ว: YOLO มีชื่อเสียงในด้านความเร็ว และในเวอร์ชันใหม่ ๆ ก็มีการปรับปรุงให้เร็วยิ่งขึ้น
ความซับซ้อน: ในขณะที่เวอร์ชันใหม่ ๆ มีความซับซ้อนมากขึ้น แต่ก็มีการให้เครื่องมือและเอกสารที่ช่วยให้ใช้ได้ง่ายขึ้น
การเลือกใช้ YOLO เวอร์ชันใดขึ้นอยู่กับความต้องการและข้อกำหนดของโปรเจกต์นั้น ๆ ตัวอย่างเช่น หากต้องการการตรวจจับที่รวดเร็วในสภาพแวดล้อมที่ไม่ซับซ้อน YOLOv3 หรือ YOLOv4 อาจจะเพียงพอ แต่ถ้าต้องการความแม่นยำสูงในสภาพแวดล้อมที่ซับซ้อน YOLOv5 หรือ YOLOv6 จะเป็นทางเลือกที่ดีกว่า
YOLO คืออะไร ความแตกต่าง ของ แต่ละ version
YOLO หรือ "You Only Look Once" เป็นอัลกอริทึมการตรวจจับวัตถุแบบเรียลไทม์ที่มีประสิทธิภาพสูงในด้านความเร็วและความแม่นยำ ถูกพัฒนาขึ้นครั้งแรกในปี 2015 โดย Joseph Redmon และทีมวิจัย YOLO ได้รับความนิยมอย่างมากในวงการคอมพิวเตอร์วิชั่นและการเรียนรู้ของเครื่อง เนื่องจากสามารถตรวจจับวัตถุได้หลายชนิดพร้อมกันในภาพเดียวอย่างรวดเร็ว