โจทย์คือเรามีลูกค้า 50,000 คน เราลองส่งอีเมล์แบบสุ่มๆไปหา 10% 5000 คน
คนตอบเมล์กลับมา 300 คน จากนั้นเอามาแบ่งกลุ่มด้วย decision tree
พบว่า การแบ่งตามอายุแบบวงกลมสีเหลืองจะทำให้ได้กำไร เพราะ Gini coefficient ต่ำเมื่อเทียบกับแบบอื่น และผ่านเกณฑ์อัตราขั้นต่ำในการตอบกลับ
สมมติว่าส่งเมล์มีค่าใช้จ่าย 0.5 บาทต่อเมล์ และได้กำไรสุทธิ 5.5 บาทต่อเมล์ถ้าลูกค้าตอบกลับ
คำถามคือ เราจะแบ่งกลุ่มอีก 45000 คนที่เหลือตามเกณฑ์นี้ยังไง แล้ว expected total net profit ของอีเมล์ทั้งสองรอบนี้เป็นเท่าไร
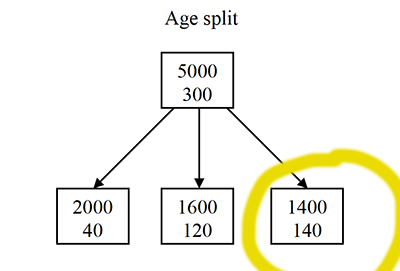
เริ่มแรกผมคำนวณอัตราการตอบเมล์ขั้นต่ำที่จะทำให้ได้กำไร ได้เท่ากับ 8.33%
ดังนั้นเฉพาะกลุ่มที่วงกลมสีเหลือง (อัตราการตอบกลับ 10% ซึ่งเกินขั้นต่ำ 8.33%)
ที่เราควรยึดเป็นเกณฑ์เอาไปใช้ทาเก็ตในรอบสองกับอีก 45000 คน
เมื่อคำนวณกำไรจาก 5000 คนแรกแล้วพบว่า
กำไรจากคนตอบ = 5.5บาท*300คน = 1650 บาท
คนไม่ตอบคิดค่าส่งเมล์ = 0.5บาท* 4700 = -2350 ดังนั้นรอบแรกเราขาดทุนอยู่ -700 บาท
คำถามคือ อีก 45000 คนเราควรแบ่งกลุ่มไปลงเกณฑ์วงกลมสีเหลืองยังไงครับ เพราะโจทย์ไม่ได้ให้ข้อมูลอื่นมา

ใครคิดออกมั่งครับโจทย์ Gini coefficient และ decision tree ใน data science
คนตอบเมล์กลับมา 300 คน จากนั้นเอามาแบ่งกลุ่มด้วย decision tree
พบว่า การแบ่งตามอายุแบบวงกลมสีเหลืองจะทำให้ได้กำไร เพราะ Gini coefficient ต่ำเมื่อเทียบกับแบบอื่น และผ่านเกณฑ์อัตราขั้นต่ำในการตอบกลับ
สมมติว่าส่งเมล์มีค่าใช้จ่าย 0.5 บาทต่อเมล์ และได้กำไรสุทธิ 5.5 บาทต่อเมล์ถ้าลูกค้าตอบกลับ
คำถามคือ เราจะแบ่งกลุ่มอีก 45000 คนที่เหลือตามเกณฑ์นี้ยังไง แล้ว expected total net profit ของอีเมล์ทั้งสองรอบนี้เป็นเท่าไร
ดังนั้นเฉพาะกลุ่มที่วงกลมสีเหลือง (อัตราการตอบกลับ 10% ซึ่งเกินขั้นต่ำ 8.33%)
ที่เราควรยึดเป็นเกณฑ์เอาไปใช้ทาเก็ตในรอบสองกับอีก 45000 คน
เมื่อคำนวณกำไรจาก 5000 คนแรกแล้วพบว่า
กำไรจากคนตอบ = 5.5บาท*300คน = 1650 บาท
คนไม่ตอบคิดค่าส่งเมล์ = 0.5บาท* 4700 = -2350 ดังนั้นรอบแรกเราขาดทุนอยู่ -700 บาท
คำถามคือ อีก 45000 คนเราควรแบ่งกลุ่มไปลงเกณฑ์วงกลมสีเหลืองยังไงครับ เพราะโจทย์ไม่ได้ให้ข้อมูลอื่นมา