March 20, 2014
Peek into China’s Plans for Top Supercomputer Shows No Slowdown
Nicole Hemsoth
This week we learned more about Japan’s exascale plans for the 2020 timeframe, but also on the contender list to be among the first to reach exascale-class computing levels is China. For now, however, the country has its sights set on continuing to dominate the list in 2015 and beyond.
To put this and the larger exascale computing momentum in context, the United States and Europe are both expecting to reach this level of computing in the early 2020s. However, without serious investment and innovation, Asia has a strong foothold, starting now with its #1 Tianhe-2 system, which dramatically bested other machines last year–and will continue to push the boundaries against its rivals in Japan.
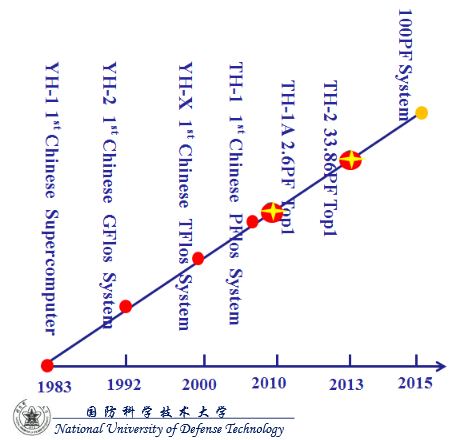
While this change the exascale tide on the international front will not come as a surprise to many, a glimpse into the future of the current far-and-away top supercomputer on the planet, the Tianhe-2, shows an ambitious upgrade cycle arriving in 2015 to bring it from 54.9 petaflops (which set quite a record when it was announced) to 100 petaflops.
While this is a remarkable feat in floating point boundary-pushing, so far it doesn’t look like there will be any new earth-shattering tech to power the tectonic compute force. However, as we’ll say repeatedly at this early point, details are still rather spotty.
Tianhe-2 is entering its second stage, as expected, with this upgrade although just how much of a kicker it would get was unknown when the development plans were described over the last year. The name is not expected to change and from what we’re able to see from the light, early details, it wouldn’t be fitting since this looks to be a refresh and upgrade versus any rip and replace of the Xeon Phi/Xeon and FT-1500 approach.
It’s been a while since we’ve taken a look at this system, so for reference the details are below to help compare some of the changes China is set to make on the road to its 100 petaflopper. The # sign next to the processors tells us how many are currently on the system.
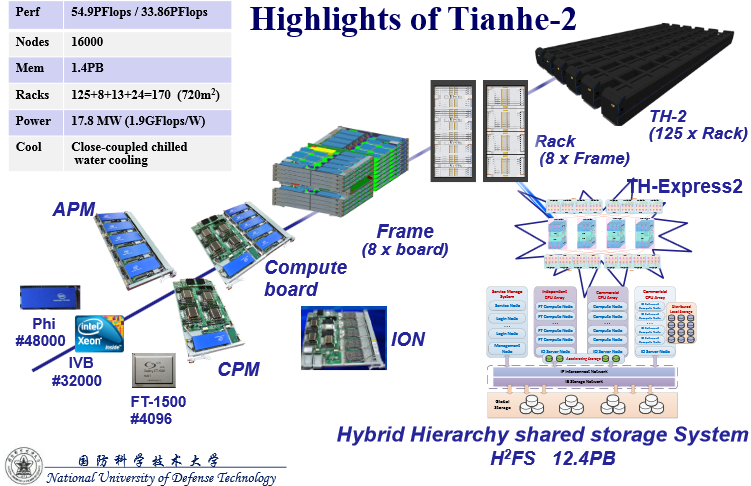
At the intimate BDEC event in Japan recently, a peek into future plans for Tianhe-2, Dr. Yutong Lu from the National University of Defense Technology in China (site of the top system) offered some details about what’s expected. While there aren’t a lot of details, the system will very possibly use the next generation Knight’s Landing (this was not confirmed by Intel or NUDT but since it’s already a Phi system and the next generation is going to offer over double the flops, this seems a natural guess since they’re not likely to rip and replace to add a new, custom architecture). If you want to do some mental math with no confirmed details (where’s the fun in it otherwise) you can guess that the newest Knight’s Landing will provide an approximately 3x boost. Swap out those 48,000 Phi cards and what do you have? A tick over 100 petaflops. Meanwhile, at Intel, someone is beating their fists, saying, “but we haven’t released those details yet!”. Fair enough, fellas. Speculation ends here.
Looking at the chart above, it’s not likely that little FT-1500 processor (Galaxy) can be expanded to play any major role in such a doubling of floating point capability since it’s just used as a front end processor. Further, the only other processor option that might be a fringe answer to this improvement is the Shenwei (as found on the #40 BlueLight machine) but it’s unlikely the 16-core processor, even after an expected upgrade cycle this year as it enters its fourth generation) will come close to offering that kind of boost.
The real story behind the Tianhe-2 kick is probably going to be around the custom TH-express interconnect, which Lu said would be getting a name upgrade (now called the TH-express+2). Whether that means it’s doubly fast or not remains to be seen. Again, we’ll report on details as soon as we have them.
Lu says China is also hard at work on the first legs of its exascale research program with the goal being to create an “advanced and feasible architecture” that falls into the target of 30GFlops per Watt.
Current funding for China’s exascale and continued HPC investments are centered on developing the fundamental algorithms and manycore parallel programming techniques required for extreme scale scientific computing. They’re also pouring additional funds into pushing boundaries in terms of their network-based research environment.
In addition to firming up their CNGrid service environment and continuing to operate the petascale Xeon/GPU Nebulae supercomputer at the National Supercomputing Center in Shenzen, Guangdong, China, the country is still hard at work on the Shenwei processors as a key item on the funding agenda.
The next generation of applications are set to focus on fusion, aircraft design, space, materials science, drug design, animation, the “mechanics of giant engineering equipment” and electromagnetic environment simulation.
The country is also focusing on big data as a key goal area, with emphasis on a large-scale in-memory computing system that sports “hybrid memory management policies.” The target application areas will focus on providing “humanoid answers” to difficult problems as well as tackling Watson-like cognitive computing challenges.
These are still early days in terms of confirmation from either vendors or centers but as always, we’ll deliver details as soon as we’re able to validate them.
Peek into China's Plans for Top Supercomputer Shows No Slowdown


เตรียมพบกับ supercomputer ใหม่ของจีน เอาไว้เทรดหุ้นไหวไหม
Peek into China’s Plans for Top Supercomputer Shows No Slowdown
Nicole Hemsoth
This week we learned more about Japan’s exascale plans for the 2020 timeframe, but also on the contender list to be among the first to reach exascale-class computing levels is China. For now, however, the country has its sights set on continuing to dominate the list in 2015 and beyond.
To put this and the larger exascale computing momentum in context, the United States and Europe are both expecting to reach this level of computing in the early 2020s. However, without serious investment and innovation, Asia has a strong foothold, starting now with its #1 Tianhe-2 system, which dramatically bested other machines last year–and will continue to push the boundaries against its rivals in Japan.
While this change the exascale tide on the international front will not come as a surprise to many, a glimpse into the future of the current far-and-away top supercomputer on the planet, the Tianhe-2, shows an ambitious upgrade cycle arriving in 2015 to bring it from 54.9 petaflops (which set quite a record when it was announced) to 100 petaflops.
While this is a remarkable feat in floating point boundary-pushing, so far it doesn’t look like there will be any new earth-shattering tech to power the tectonic compute force. However, as we’ll say repeatedly at this early point, details are still rather spotty.
Tianhe-2 is entering its second stage, as expected, with this upgrade although just how much of a kicker it would get was unknown when the development plans were described over the last year. The name is not expected to change and from what we’re able to see from the light, early details, it wouldn’t be fitting since this looks to be a refresh and upgrade versus any rip and replace of the Xeon Phi/Xeon and FT-1500 approach.
It’s been a while since we’ve taken a look at this system, so for reference the details are below to help compare some of the changes China is set to make on the road to its 100 petaflopper. The # sign next to the processors tells us how many are currently on the system.
At the intimate BDEC event in Japan recently, a peek into future plans for Tianhe-2, Dr. Yutong Lu from the National University of Defense Technology in China (site of the top system) offered some details about what’s expected. While there aren’t a lot of details, the system will very possibly use the next generation Knight’s Landing (this was not confirmed by Intel or NUDT but since it’s already a Phi system and the next generation is going to offer over double the flops, this seems a natural guess since they’re not likely to rip and replace to add a new, custom architecture). If you want to do some mental math with no confirmed details (where’s the fun in it otherwise) you can guess that the newest Knight’s Landing will provide an approximately 3x boost. Swap out those 48,000 Phi cards and what do you have? A tick over 100 petaflops. Meanwhile, at Intel, someone is beating their fists, saying, “but we haven’t released those details yet!”. Fair enough, fellas. Speculation ends here.
Looking at the chart above, it’s not likely that little FT-1500 processor (Galaxy) can be expanded to play any major role in such a doubling of floating point capability since it’s just used as a front end processor. Further, the only other processor option that might be a fringe answer to this improvement is the Shenwei (as found on the #40 BlueLight machine) but it’s unlikely the 16-core processor, even after an expected upgrade cycle this year as it enters its fourth generation) will come close to offering that kind of boost.
The real story behind the Tianhe-2 kick is probably going to be around the custom TH-express interconnect, which Lu said would be getting a name upgrade (now called the TH-express+2). Whether that means it’s doubly fast or not remains to be seen. Again, we’ll report on details as soon as we have them.
Lu says China is also hard at work on the first legs of its exascale research program with the goal being to create an “advanced and feasible architecture” that falls into the target of 30GFlops per Watt.
Current funding for China’s exascale and continued HPC investments are centered on developing the fundamental algorithms and manycore parallel programming techniques required for extreme scale scientific computing. They’re also pouring additional funds into pushing boundaries in terms of their network-based research environment.
In addition to firming up their CNGrid service environment and continuing to operate the petascale Xeon/GPU Nebulae supercomputer at the National Supercomputing Center in Shenzen, Guangdong, China, the country is still hard at work on the Shenwei processors as a key item on the funding agenda.
The next generation of applications are set to focus on fusion, aircraft design, space, materials science, drug design, animation, the “mechanics of giant engineering equipment” and electromagnetic environment simulation.
The country is also focusing on big data as a key goal area, with emphasis on a large-scale in-memory computing system that sports “hybrid memory management policies.” The target application areas will focus on providing “humanoid answers” to difficult problems as well as tackling Watson-like cognitive computing challenges.
These are still early days in terms of confirmation from either vendors or centers but as always, we’ll deliver details as soon as we’re able to validate them.
Peek into China's Plans for Top Supercomputer Shows No Slowdown